PinnedHair ParrainAnalytics VidhyaPredicting stocks: Not a trivial matter!Surely, you have probably seen a lot of tutorials on using Time Series Analysis to predict the stock market. In reality, even field…May 29, 20201May 29, 20201
PinnedHair ParrainAnalytics VidhyaA Complete Introduction to Black-Scholes Model — For QuantsA Mathematical Perspective with Stochastic Calculus and PythonMar 7Mar 7
PinnedHair ParrainTowards Data ScienceThe Data Science Trilogy: NumPy, Pandas and Matplotlib basicsSo you are new to Python. Or perhaps you are already familiar with these libraries, but wanted to get a quick refresher. Whatever the case…Apr 21, 2021Apr 21, 2021
PinnedHair ParrainTowards Data ScienceA Quick Guide to Beautiful Scatter Plots in PythonVisualizing worldwide Life Expectancy vs GPD per capitaJan 12, 2023Jan 12, 2023
Hair ParrainAnalytics VidhyaUnderstanding the BLEU and ROUGE Metrics for Large Language Models in 10 min using ChatGPT with…By using GPT-4, ScholarAI, and SmartSlidesAug 5, 2023Aug 5, 2023
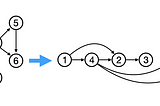
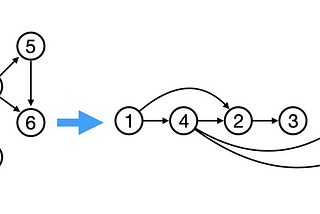
Hair ParrainAnalytics VidhyaComparing Topological Sort Loop-based and Recursive ImplementationsWith examples in Java and PythonMar 21, 2023Mar 21, 2023
Hair ParrainAnalytics VidhyaQuick GIT is all you NEEDOkay, so you have come here because you want to learn Git/Github. So instead of writing a 10 lines paragraph about it, let’s get to the…Mar 26, 2021Mar 26, 2021
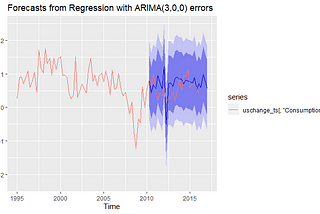
Hair ParrainAnalytics VidhyaA Complete Introduction To Time Series Analysis (with R):: Exogenous modelsWe have come pretty far into our analysis of univariate time series. So far, we have considered some sort of time-based stochastic process…Mar 15, 20211Mar 15, 20211
Hair ParrainAnalytics VidhyaA Complete Introduction To Time Series Analysis (with R):: SARIMA modelsIn the last article, we saw one important useful extension to the ARMA models: the Autoregressive Integrated Moving Average or ARIMA…Feb 27, 2021Feb 27, 2021
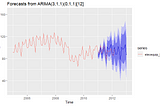
Hair ParrainAnalytics VidhyaA Complete Introduction To Time Series Analysis (with R):: ARIMA and SARIMA modelsIn the last section, we discussed model selection for ARMA(p,q) models by using the AIC, AICc, BIC, which are metric functions based on…Feb 22, 2021Feb 22, 2021